Newsletter
Genomeditierung, Proteomik, nicht-codierende RNAs: Neues zu DNA, RNA und Proteinen
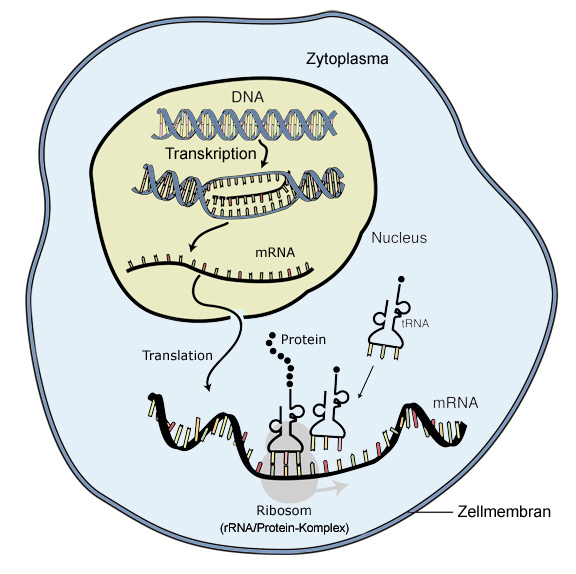
DNA, RNA, Transkription, Translation, Bild: Wikimedia (CCO)
DNA, RNA und Proteine - das sind die Bausteine des Lebens. Dieser Artikel gibt nach einer kurzen Auffrischung des Lehrbuch-Wissens Einblick in aktuelle Forschung und Entwicklungauf diesem Gebiet. Unter anderem werden moderne DNA-Sequenzierverfahren und Epigenetik behandelt, nicht-codierende RNAs und Proteomik.
DNA, RNA, Proteine – eine kurze Einleitung
Der Bauplan des Lebens ist in der Sequenz der Desoxyribonukleinsäure (DNA) festgelegt und in allen Zellen eines Organismus gleich. So etwa besteht ein erwachsener Mensch aus rund 100 Billionen Zellen, die alle die gleiche Information in ihrer DNA gespeichert haben. Je nach Gewebe oder Organ unterscheiden sich Aussehen und Funktionen der Zellen jedoch, was nur durch eine streng kontrollierte Regulation der Genexpression während Wachstum und Entwicklung möglich ist. Die doppelsträngige DNA ist stark kompaktiert und beim Menschen zu 46 fadenförmigen Chromosomen organisiert. Sie befindet sich bei Eukaryonten im Zellkern. Das menschliche Genom besteht aus etwa drei Milliarden Basenpaaren. Würde man die gesamte DNA aller menschlichen Zellen aneinanderreihen, so würde das einen Faden mit einer Länge ergeben, die 640-mal von der Erde zur Sonne reicht. Alle 46 Chromosomen einer einzigen menschlichen Zelle aneinandergelegt ergäben immerhin noch einen DNA-Faden von etwa zwei Metern Länge.
Die Ribonukleinsäure (RNA) enthält die aus der DNA kopierte Information (bis auf wenige Ausnahmen) in einem Einzelstrang. RNA ist bei Eukaryoten nicht nur im Zellkern zu finden, denn sie wird – im Gegensatz zur DNA – ins Zytoplasma transportiert. Messenger-RNA (mRNA), Transfer-RNA (tRNA) und Ribosomale-RNA (rRNA) sind schon lange als zentrale Akteure in der Proteinbiosynthese bekannt. Heute weiß man allerdings, dass RNA auch regulatorische Funktionen haben kann, und daran wird aktuell intensiv geforscht.
Proteine (Eiweiße) stellen die Bausubstanz unseres Körpers dar und bestimmen auch Form, Struktur und Funktion der Zellen. Proteinesind aus 20 verschiedenen Aminosäuren aufgebaut. Manche davon können vom Körper selbst hergestellt werden, andere - sogenannte essentielle Aminosäuren - jedoch nicht. Diese müssen daher in Form von Nahrung zugeführt werden.
Proteinbiosynthese: Von der DNA zum Protein
Bereits 1958 stellte Francis Crick das zentrale Dogma der Molekularbiologie zum Informationsfluss zwischen DNA, RNA und Protein auf: Es besagt, dass bei der allgemeinen Übertragungsart (bei der Proteinbiosynthese) die sequenzielle Information von DNA über RNA zum Protein übertragen wird. Auch spezielle Übertragungsarten wie beispielsweise das Umschreiben von RNA in DNA durch reverse Transkriptase wurden von Crick schon beschrieben. Heute wird immer mehr zur Komplexität des Zusammenspiels von DNA, RNA und Protein bekannt, das Dogma aber hat noch immer seine Gültigkeit [1]. Transkription und Translation als Schritte der Biosynthese sind aus Lehrbüchern allgemein bekannt.
Aktuelle Forschung und Entwicklung: DNA
Epigenetische Prozesse steuern die Genexpression
Um die gesamte DNA einer Zelle in ihren Zellkern packen zu können, muss diese eine sehr kompakte Form annehmen. Dies wird dadurch erreicht, dass die DNA aufgerollt und um Proteine gewunden wird. Etwa die Hälfte dieser Proteine sind sogenannte Histone. So entstehen Nukleosomen (DNA zweimal um ein Oktamer aus Histonen gewunden), die noch kompakteren Solenoide (Verdichtungen mehrerer Nukleosomen) und DNA-Schleifen, die sich weiter zu den Chromosomen verdichten. Die DNA besteht je nach Verpackungsgrad aus Abschnitten, die von DNA-Polymerasen besser oder schlechter abgelesen werden können. Euchromatin ist etwas lockerer verpackt und zeichnet einen DNA-Bereich aus, in dem vermehrt Gene abgelesen werden. Heterochromatin dagegen ist transkriptionell inaktiv, das heißt, die DNA ist so dicht aufgerollt, dass sie für Polymerasen nicht zugänglich ist.
Seit der Entschlüsselung des menschlichen Genoms im Jahr 2003 ist die Sequenz unserer DNA aus rund drei Milliarden Buchstaben-Paaren bekannt. Auf anfängliche Euphorie erfolgte jedoch bald die Ernüchterung: Der Mensch ist mehr als die Summe seiner rund 25.000 Gene, denn Gene steuern nicht nur, sondern sie werden auch gesteuert. Dieses Phänomen versucht der Fachbereich der Epigenetik zu erklären, die sich seit den frühen 2000er Jahren mit den Veränderungen am Chromatin und an der DNA beschäftigt. Die Epigenetik erforscht die Mechanismen der Genaktivität - also welche Gene wie stark abgelesen werden - die keine Änderung in der DNA-Sequenz beinhalten und trotzdem vererbbar sein können. Wichtige Grundlagen zur Epigenetik und Aktuelles zu ihrer Rolle bei Entwicklung, Differenzierung und bei Krankheit sowie die Wirkung der Nahrung auf unsere Gene gibt es im Foliensatz „Epigenetik“ von Open Science.
Neue Erkenntnisse durch die Epigenetik haben unser Verständnis zur Entwicklung von Organismen verbessert und haben auch in der medizinischen Forschung – beispielsweise bei Krebserkrankungen [4] – zu neuen Ansätzen geführt. So konnten “Whole-Genome” Analysen von Krebsgewebe beispielsweise zeigen, dass manche Krebsarten Mutationen in regulativen epigenetischen Elementen aufweisen. Es sind aber heute bei weitem noch nicht alle Mechanismen erforscht, wie die Zelle kontrolliert und welche genetische Information abgelesen wird, und die Epigenetik ist und bleibt einer der Hot Spots der aktuellen Forschung.
Moderne DNA-Sequenzierverfahren
Nach der Entschlüsselung des gesamten Genoms des Menschen im Jahr 2003 wurden die DNA-Sequenziermethoden kontinuierlich weiterentwickelt. Das so genannte Next-Generation-Sequencing (NGS) ermöglicht es heute, Analysen ganzer Genome rasch und kostengünstig durchzuführen. Konnte früher bei der so genannten Sanger-Methode nur eine Sequenz analysiert werden, so ermöglichen es im Gegensatz dazu die Sequenz-Analyseverfahren von heute, viele Sequenzen gleichzeitig aus Gemischen zu sequenzieren. Die DNA-Sequenzierung ist heute noch dazu relativ kostengünstig und schnell. Bei den modernen Sequenzier-Verfahren wird zwischen dem so genannten Next Generation Sequencing (NGS), dem Third Generation Sequencing und dem Fourth Generation Sequencing unterschieden [2, 3].
Das Next Generation Sequencing hat im Vergleich zu Sanger unheimlich großes Potential: Das gesamte menschliche Genom kann an einem einzigen Tag sequenziert werden. Dies erfolgt durch Ultra-Hochdurchsatz-Methoden, bei denen Moleküle an Oberflächen gebunden und hochauflösende Bilder aufgenommen werden. Es ist sowohl das Sequenzieren von DNA als auch von cDNA (DNA, die mithilfe des Enzyms Reverse Transkriptase komplementär zur Ausgangs-RNA synthetisiert wird) möglich, und je nach Methode wird durch Synthese, Hybridisierung oder Ligation sequenziert.
Beim Third Generation Sequencing wird mithilfe von Nanoporensequenzierung die DNA durch eine mikroskopisch kleine Pore einer Membran gefädelt. Je nachdem, wie der Ionenstrom von einer Seite der Membran auf die andere Seite von ihr beeinflusst wird, können die Basen der DNA identifiziert werden. Beim Fourth Generation Sequencing ist sogar schon paralleles Sequenzieren direkt in der Zelle möglich.
Die Genschere CRISPR/Cas: Revolution der Genomeditierung
Die Genschere CRISPR/Cas stellt eine neue Methode zur Genomeditierung dar und wird als Revolution der Gentechnik gefeiert. Mit ihr kann DNA einfach, schnell, und vor allem genau an einer bestimmten Stelle verändert werden, und das in nahezu allen lebenden Zellen und Organismen. Mit dem neuen Präzisions-Werkzeug kann DNA gezielt im Genom entfernt oder eingefügt werden. CRISPR/Cas wird mittlerweile standardmäßig in Forschung und Entwicklung eingesetzt und hat maßgeblich dazu beigetragen, dass diese beschleunigt wurden. Vor allem bei der Heilung von Erbkrankheiten und der Züchtung von Pflanzen, die z.B. der Klimakrise trotzen, wird große Hoffnung in CRISPR/Cas gesetzt. Bei der Anwendung dieser Methode gibt es allerdings auch ethische Bedenken.
DNA als “Falle” für Eindringlinge
Folgendes Phänomen fasziniert schon seit längerem nicht nur die Welt der Immunologen: Neutrophile, eine besondere Art von Säugetier-Immunzellen, können ein Gemisch aus Proteinen und ihrer eigenen DNA „auswerfen“, um so pathogene Bakterien zu bekämpfen [5]. Diese “Neutrophil Extracellular Traps” (Neutrophile extrazelluläre Fallen), oder NETs, machen sich die fadenförmige Struktur von DNA zunutze und formen ein Netz aus ausgewickeltem Chromatin. Während die eindringenden Bakterien sich in dem Gewirr aus Erbmaterial verheddern und sich nicht im Körper ausbreiten können, sorgen Enzyme dafür, dass bakterielle Virulenzfaktoren neutralisiert und weitere Zellen der Immunabwehr aktiviert werden. Beim Freisetzen der NETs platzt die Zelle meistens auf und stirbt, manche Neutrophile überleben diesen Prozess jedoch und verteilen sogar noch das DNA-Netz. Das unkontrollierte Freisetzen von NETs kann auch negative Auswirkungen auf den eigenen Körper haben, beispielsweise durch Förderung von Blutgerinnung in engen Blutgefäßen.
Aktuelle Forschung und Entwicklung: RNA
Die wichtige Rolle von mRNA, tRNA und rRNA bei der Proteinbiosynthese ist schon lange bekannt. Insgesamt codieren allerdings nur rund 2-5% unseres Genoms für Proteine und werden somit in mRNA umgeschrieben, der Rest der DNA wurde lange als „Junk“, also Abfall, bezeichnet. Heute weiß man allerdings, dass RNA-Moleküle viel mehr sind als Botschafter zwischen DNA und Protein und auch regulatorische Funktionen ausüben können. Man nimmt an, dass ungefähr 80% des gesamten menschlichen Genoms zu non-codingRNA (ncRNA; nicht-kodierende RNA) transkribiert wird - einer Vielzahl an RNA-Molekülen mit unterschiedlicher Länge, Funktion und auch Lokalisation in der Zelle [6].
Kleine nicht-codierende RNAs
Ein Meilenstein der RNA-Forschung war die Entdeckung von micro-RNAs (miRNAs) im Jahr 1993, die zu den kleinen RNAs zählen. Es zeigte sich, dass RNA-Moleküle mit einer Länge von etwa 22 Nukleotiden wesentlich für die Steuerung der Entwicklungsschritte des Fadenwurms C. elegans waren. miRNAs können mit mRNAs interagieren und spielen bei vielen Mechanismen eine Rolle. Ein Beispiel dafür ist die sogenannte RNA-Intereferenz (RNAi, RNA Silencing), die ebenfalls in C. elegans sowie in Pflanzen entdeckt wurde. Wie der Name schon impliziert, wird bei RNAi mithilfe von RNA die Expression von mRNAs unterdrückt. Dieser Prozess kann mithilfe verschiedener kurzer RNAs ablaufen: miRNAs oder small-interfering-RNA (siRNAs). In beiden Fällen werden kurze (21-25 Nukleotide) RNA-Stücke produziert, die sich in weiterer Folge mit einem Protein verbinden und dann als gemeinsamer Komplex, genannt RNA-Induced-Silencing-Complex (RISC), an einen mRNA-Strang binden. Die Bindung der siRNA mit der Ziel-RNA ist sehr genau, weil diese über die komplementäre Sequenz im RNA-RISC Komplex erfolgt. Im Gegensatz dazu gehen Proteinkomplexe mit miRNAs unpräzisere Bindungen ein und können mit mehreren unterschiedliche mRNAs interagieren. Nachdem diese Bindung stattgefunden hat, wird die mRNA durch Enzyme gespalten oder die Expression gestoppt. RNAi wird heute intensiv in der Forschung eingesetzt, um gezielt in die Genexpression einzugreifen [7].
Im Jahr 2006 wurden kleine RNAs entdeckt, die etwas länger als miRNAs und siRNAs sind: die piwi-interacting RNAs (piRNAs). Diese bilden einen Kopmlex mit PIWI-Proteinen und kommen hauptsächlich in Geschlechtszellen vor.
Die small nuclear ribonucleic acid (snRNAs) sind etwa 100 bis 300 Basenpaare lange RNA-Moleküle und kommen im Zellkern vor. Small nucleolar ribonucleic acid (snoRNAs) hingegen sind – wie der Name schon sagt – meist in den Nucleoli zu finden. Dort prozessieren und modifizieren sie andere Ribonukleinsäuren - insbesondere ribosomale RNA (rRNA). Auch die snoRNAs fungieren als „guide RNA“: Sie geleiten Enzyme an die richtige Stelle der RNA.
Lange nicht-codierende RNAs
Eine weitere äußerst diverse Klasse von RNA-Molekülen sind long-non-coding-RNAs (lncRNAs). Auch hier ist der Name Programm: Diese RNA-Stücke sind mindestens 200 Nukleotide lang und kodieren für keine Proteine. In ihrer Funktion variieren die verschiedenen lncRNAs sehr, und es werden laufend neue entdeckt. Sie spielen eine Rolle beim Spleißen von mRNA und bei der Modifikation von Chromatin. So wird zum Beispiel bei weiblichen Säugetieren eine der zwei Kopien des X-Chromosoms durch lncRNA stillgelegt. Dadurch wird eine Überproduktion von Genen auf dem X-Chromosom verhindert.
RNAs im CRISPR/Cas System
Auch bei der Genschere CRISPR/Cas9 spielen RNAs eine wichtige Rolle: Die crRNA bindet an eine trans-activating cRNA (tracrRNA) und wird dann von Cas9 gebunden. Da die crRNA und tracrRNA Cas9 an die richtige Stelle der DNA führen, wird deren Komplex oft vereinfacht auch als guideRNA bezeichnet.
RNA-Welt-Hypothese
Der genetische Bauplan ist in der DNA verschlüsselt. Die darin enthaltene Information muss zuerst abgelesen und in ein RNA-Molekül übertragen werden, damit sie in weiterer Folge in ein Protein übersetzt werden kann. Betrachtet man aber diesen Prozess etwas genauer, stellt sich die Frage: Wie kann das beim allerersten Organismus funktioniert haben? Immerhin braucht es für die Transkription Proteine, die selbst erst produziert werden müssen. Und für die Translation werden RNA-Moleküle benötigt, die mit Proteinen interagieren und Reaktionen katalysieren. Wie kann es also zum Beginn des Lebens ausgesehen haben, oder anders gefragt: Was war zuerst da: DNA oder RNA?
Das „Henne-Ei-Problem“ beschäftigt die Forschung schon seit vielen Jahren. Einer der bisher vielversprechendsten Ansätze ist die RNA-Welt-Hypothese, die auf der frühen Entdeckung Francis Cricks basiert: Dieser spekulierte, dass RNA auch als Gen und Enzym auftreten kann. RNA könnte also als Enzym fungiert und sich selbst katalysiert haben. Der Biochemiker und Nobelpreisträger Gerald Joyce prägte 1989 den Begriff RNA-Welt-Hypothese, indem er alle wissenschaftlichen Ergebnisse zur RNA zusammentrug. Kritiker blieben allerdings skeptisch, denn was war vor der RNA?
Die österreichische Wissenschaftlerin Renée Schroeder hat zur Erforschung der RNA sehr viel beigetragen und stellte anhand von Beweisen auch Hypothesen und Theorien auf: RNA kann sowohl als Bauplan dienen als auch enzymatisch aktiv sein. Die regulatorischen Fähigkeiten der RNA sowie die Tatsache, dass RNA formbar und aktiv ist, lassen Veränderungen zu. Und ohne Veränderung kein Leben, ist eine der Kernaussagen von Schroeder.
Die frühe Existenz der RNA wird dadurch untermauert, dass sie der Bestrahlung mit UV-Licht gut standhält. RNA-Basen sind in der Lage, UV-Licht zu absorbieren und somit die RNA vor Brüchen schützen. Die UV-Strahlung zur Frühzeit der Erde war etwa hundertmal so stark wie heute. Die Unempfindlichkeit des Makromoleküls RNA gegenüber dieser Strahlung könnte demnach ein Beweis dafür sein, dass RNA einen selektiven Vorteil in der Entwicklung gegenüber anderen Molekülen hatte. 2009 gelang es, im Labor zwei RNA Stränge herzustellen, die sich gegenseitig vervielfältigten, was auch für die Hypothese der RNA-Welt spricht. Auch die Tatsache, dass im Labor Pyrimidin-Nukleotiden (Uracil, Thymin, Cytosin) unter präbiotisch plausiblen Bedingungen hergestellt werden konnten, könnte ein weiterer Beweis für eine Ursuppe sein, in der sich RNA-Bestandteile bildeten und zusammenfügten. Dass Erbinformationen mancher Viren bis heute aus RNA bestehen (zb: HIV-Virus, Rhinovirus), ist ein weiteres Indiz, das dafür spricht.
Aktuelle Forschung und Entwicklung: Proteine
Proteomik
Als Endprodukt der Proteinbiosynthese stellen Proteine die Schlüsselfiguren in fast allen Stoffwechselvorgängen im Körper dar. Durch das Zusammenspiel verschiedener Proteine entsteht ein riesiges, dynamisches System in jeder Zelle und jedem Organismus. Die Gesamtheit aller in einer Zelle oder einem Lebewesen unter definierten Bedingungen und zu einem definierten Zeitpunkt vorliegenden Proteine wird als Proteom bezeichnet. Das Forschungsfeld der Proteomik beschäftigt sich mit der Untersuchung des Proteoms mit biochemischen Methoden und hat es sich zur Aufgabe gemacht, sämtliche Proteine im Organismus zu katalogisieren und ihre Funktionen zu entschlüsseln. Im Gegensatz zur DNA unterscheidet sich das Proteom von Zelle zu Zelle und ändert sich im Lauf der Zeit. Einer der wichtigsten Aspekte der Proteomik-Forschung ist aktuell die Analyse und Beobachtung von Krankheitsverläufen.
Transkriptionsfaktoren
Ein weiterer Schwerpunkt der Proteinforschung ist nach wie vor die Untersuchung der Interaktionen von Proteinen mit DNA und ihre Rolle bei der Genexpression. Proteine, die an DNA binden und die Transkription eines oder mehrerer Gene positiv oder negativ regulieren, werden Transkriptionsfaktoren (TF) genannt. Sie können die Genaktivität durch direkte Bindung an die DNA oder indirekt – durch Interaktion mit Histonen oder microRNA – steuern. Transkriptionsfaktoren nehmen eine wichtige Rolle ein, um die Proteinproduktion in einer Zelle bzw. einem Organismus zu kontrollieren. Treten hier Fehler auf, kann dies schwerwiegende Folgen haben und in verschiedensten Krankheiten resultieren. Eine weitere Erforschung des komplexen Netzwerks der Transkriptionsfaktoren und ihres Zusammenspiels eine wichtige Voraussetzung, um molekulare Prozesse in Zukunft noch besser zu verstehen. Dieses Wissen kann dann in weiterer Folge für medizinische Vorsorge und Therapie genutzt werden.
Glykoproteomik: „Gezuckerte“ Proteine
Die ganz junge Forschungsdisziplin der Glykoproteomik beschäftigt sich mit der einzigartigen Verbindung zwischen Proteinen und Zuckermolekülen. Über die Hälfte aller Proteine in unseren Zellen sind mit Zuckern versehen, man spricht von Glykosylierung. Das Anhängen eines Zuckers an ein Protein kann dessen Form und Funktion verändern und beeinflusst somit auch die Kommunikation zwischen Zellen und deren Umgebung. Bei vielen Krankheiten, wie etwa Krebs, ist oft die Ausbildung einer Zuckerstruktur fehlerhaft. Die Glykoproteomik könnte somit wertvolle Erkenntnisse zu Krebs und Infektionskrankheiten liefern, so die Hoffnung.
Kleine Geschichte: Wichtige Entdeckungen rund um DNA, RNA und Proteine
- 1819 wurde die erste Aminosäure Leucin isoliert. Bis die letzte der 20 Aminosäuren, die an der Proteinbiosynthese beteiligt sind, entdeckt wurden, vergingen noch über 100 Jahre.
- 1838 beschrieb der dänische Chemiker Gerardus Johannes Mulder zum ersten Mal die chemische Struktur von Proteinen. Der Name „Protein“ stammt jedoch von dem schwedischen Chemiker Jöns Jakob Berzelius.
- 1866 publizierte Gregor Mendel die Ergebnisse seiner Kreuzungsexperimente mit Erbsen und postulierte grundlegende Gesetzmäßigkeiten der Vererbung.
- 1869 isolierte Friedrich Miescher erstmals „Nuklein“ aus den Kernen weißer Blutkörperchen.
- 1882 entdeckte Walther Flemming die Chromosomen mit ihren fadenähnlichen Strukturen.
- 1902 entwickelten Walter Stanborough Sutton und Theodor Boveri die Chromosomentheorie der Vererbung.
- 1902 stellten der Prager Franz Hofmeister und der Deutsche Emil Fischer unabhängig voneinander ihre Theorien zur Proteinstruktur aus Aminosäurenketten mit einer Peptidbindung vor.
- 1909 prägte Wilhem Johannsen den Begriff Gen.
- 1929 entdeckte Phoebus Levene die Nukleotide als Einheiten der DNA.
- 1944 erbrachte Oswald Avery den Beweis dafür, dass die DNA der Träger der Erbsubstanz ist.
- 1949 bestimmte Frederick Sanger die Aminosäurensequenz des Proteins Insulin.
- 1951 veröffentlichten Linus Pauling, Robert Corey und Herman Branson ihr Modell zur Sekundärstruktur von Proteinen (a-Helix, b-Faltblatt).
- 1953 stellten James Watson und Francis Crick ihr Modell der DNA-Doppelhelix vor, basierend auf Daten von Rosalind Franklin.
- 1959 erhielten Severo Ochoa und Arthur Kornberg den Nobelpreis für Medizin für ihre Studien zur RNA Synthese mittels RNA-Polymerasen. Erst 2006 wurde diese durch Roger Kornberg vollständig aufgeklärt, er erhielt dafür den Nobelpreis in Chemie.
- 1959 gelang es Max F. Perutz, die dreidimensionale Struktur von Hämoglobin aufzuklären. Dafür erhielt er 1962 gemeinsam mit John Kendrew den Nobelpreis in Chemie.
- 1968 erkannten Francis Crick, Leslie Orgel und Carl Woese RNA als wichtigen Bestandteil der Biogenese.
- 1969 gelang Jonathan Beckwith die Isolierung eines einzelnen Gens aus E.coli.
- 1972 wurde die Grundlage für die Gentechnik gelegt, als Paul Berg und andere ForscherInnen DNA-Fragmente verschiedener Lebewesen kombinierten.
- 1977 stellte Frederic Sanger eine Methode zur Sequenzierung der DNA vor.
- 1978 verwendete Kurt Wüthrich mit seinem Team die Kernmagnetresonanz-Spektroskopie als Alternative zur Röntgenkristallographie, um Proteinstrukturen aufzuklären. Dafür erhielt er 2002 den Nobelpreis in Chemie.
- 1983 entwickelte Kary Mullis die Polymerase-Kettenreaktion, eine Methode, um DNA zu vervielfältigen.
- 1986 stellte Walter Gilbert die RNA-Welt-Hypothese auf.
- 1989 analysierte Gerald Joyce Funktionen der RNA und lieferte Beweise für die RNA-Welt-Hypothese.
- 1989 bekamen Sidney Altmann und Thomas R. Cech den Nobelpreis in Chemie für ihre Entdeckung der katalytisch aktiven RNA-Moleküle, der sogenannten Ribozyme.
- 1990 wurde der erste Gentherapie-Versuch am Menschen unternommen.
- 1993 bekam Michael Smith den Nobelpreis für die Entwicklung der zielgerichteten Mutagenese. Diese Methode erlaubte die gezielte Veränderung von DNA.
- 1993 erhielten R.Roberts und P.Sharp den Nobelpreis für Medizin für ihre Studien zur RNA Prozessierung in Eukaryonten.
- 1994 wurde der Begriff „Proteom“ vom Australischen PhD-Studenten Marc Wilkins geprägt.
- 1996 wurde das Genom der Bäckerhefe, Saccharomyyces cerevisiae, von einem internationalen Team entschlüsselt.
- 1998 veröffentlichte Roderik MacKannon die ersten Aufnahmen eines Ionenkanals einer Nervenzelle. Dafür erhielt er 2003 den Nobelpreis in Chemie.
- 2001 wurde das menschliche Genom von ForscherInnen des Human Genome Project und dem Team um Craig Venter teilweise entschlüsselt und veröffentlicht.
- 2002 wurde das Genom der Maus sequenziert.
- 2003 erschien die vollständige Sequenz des menschlichen Genoms.
- 2006 wurde durch Roger Kornberg die RNA Synthese vollständig aufgeklärt, er erhielt dafür den Nobelpreis in Chemie.
- 2012 wurde von Emmanuelle Charpentier und Jennifer Doudna CRISPR/Cas als neues Genome Editing-Verfahren beschrieben.
as, 23.12.2019
Quellenangaben
Referenzen
[1] Cobb M. (2017). 60 years ago, Francis Crick changed the logic of biology. PLoS biology, 15(9), e2003243. doi:10.1371/journal.pbio.2003243
[2] Mignardi M. and Nilsson M.: Fourth-generation sequencing in the cell and the clinic (2014). Genome Med.; 6(4): 31.
[3] Heather JM and Chain B.: The sequence of sequencers: The history of sequencing DNA: Genomics. 2016 Jan; 107(1): 1-8
[4] Roberti A., Valdes AV, Torrecillas R. et al.: Epigenetics in cancer therapy and
Nanomedicine (2019). Clinical Epigenetics (2019) 11:81,https://doi.org/10.1186/s13148-019-0675-4
[5] Brinkmann, V. et al. Neutrophil extracellular traps kill bacteria. Science 303, 1532–1535 (2004). This is the first study to describe NETs.
[6] Morris KV, Mattick JS. The rise of regulatory RNA. Nat Rev Genet. 2014;15(6):423–437. doi:10.1038/nrg3722
[7] Siomi H. and Siomi M C: On the road to reading the RNA-interference code (2009). Nature, 457(7228), 396-404.